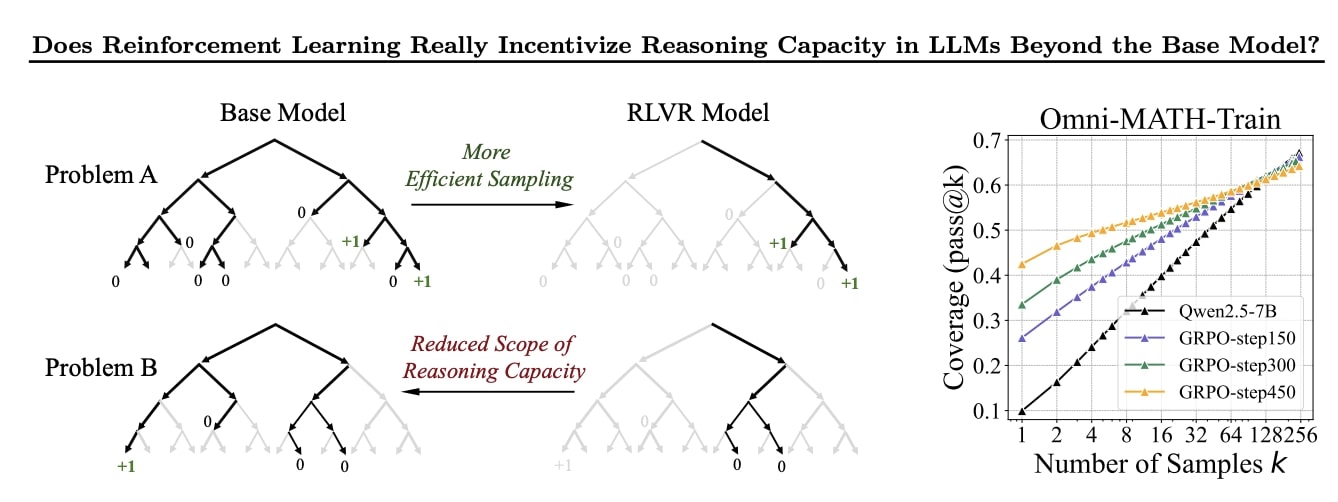
Reinforcement Learning does NOT make the base model more intelligent and limits the world of the base model in exchange for early pass performances. Graphs show that after pass 1000 the reasoning model is surpassed by the base.
Above – Figure 1: (Left) The effect of RLVR on LLM’s reasoning ability. Search trees are generated by repeated sampling from the base and RLVR-trained models for a given problem. Grey indicates paths that are unlikely to be sampled by the model, while black indicates paths that are likely to be sampled. Green indicates correct paths, which has positive rewards. Our key finding is that all reasoning paths in the RLVR model are already present in the base model. For certain problems like
Problem A, RLVR training biases the distribution toward rewarded paths, improving sampling efficiency. However, this comes at the cost of reduced scope of reasoning capacity: For other problems like Problem B, the base model contains the correct path, whereas that of the RLVR model does not. (Right) As RLVR training progresses, the average performance (i.e., pass@1) improves, but the coverage of solvable problems (i.e., pass@256) decreases, indicating a reduction in the model’s reasoning upper bound.
RLVR (Reinforcement Learning with Verifiable Rewards) is widely regarded as a promising approach to enable LLMs to continuously self-improve and acquire novel reasoning capabilities. Researchers systematically investigate the reasoning capability boundaries of both base and RLVR models across a wide range of LLM families and benchmarks, using the pass@k metric coupled with manually checked CoTs. Surprisingly, they demonstrate that RLVR does not elicit fundamentally new reasoning patterns. Instead, RL primarily enhances the efficiency of LLMs in sampling existing correct reasoning paths encoded in the base model. Consequently, the reasoning boundary remains limited by the base model’s capabilities. The in-depth analysis reveals that current RL algorithms are far from achieving the optimal sampling efficiency, defined by the reasoning boundary of the base model. They also show that distillation plays a significant role in introducing new reasoning patterns and expanding the reasoning boundary. These findings highlight a critical limitation of RLVR in advancing LLM reasoning abilities, suggesting that a new paradigm may be necessary to fully surpass the capabilities of base models.


Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.