



Now Reading: Rapid Advancements in Large Language Models Reshape AI Landscape
-
01
Rapid Advancements in Large Language Models Reshape AI Landscape
Rapid Summary
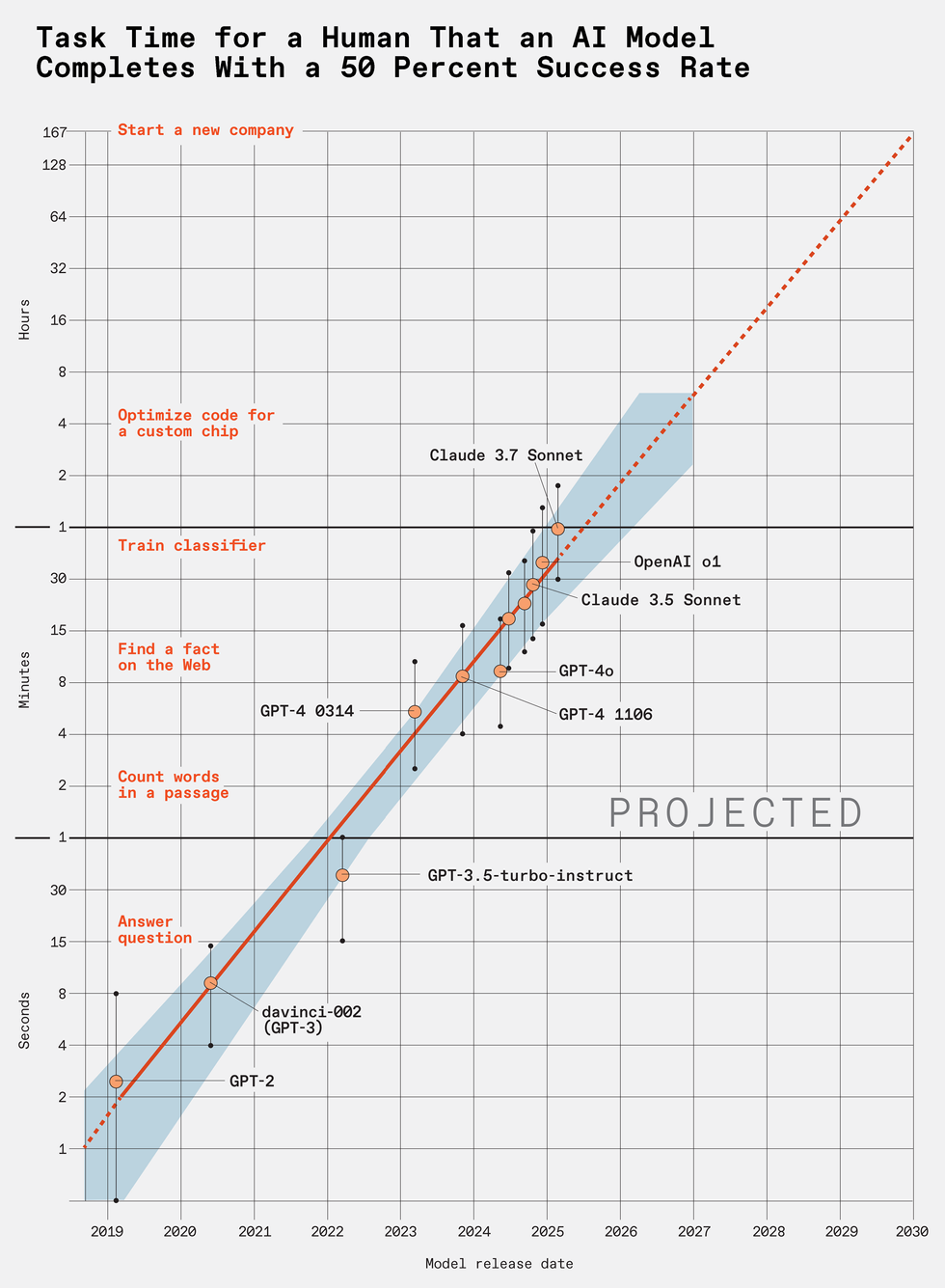
- Exponential Growth: Research by Model Evaluation & Threat Research (METR) indicates the capabilities of large language models (LLMs) are doubling every seven months,with key findings published in a March paper titled Measuring AI Ability to Complete Long Tasks.
- Future Impact: By 2030, advanced LLMs may achieve 50% reliability in completing complex tasks equivalent to one human month of work within days or hours. These tasks could range from creating companies to writing novels or improving LLMs themselves.
- Task Messiness: “Messy” real-world tasks present challenges for LLMs due to their complexity and structure, but overall advancements remain meaningful.
- Risks vs. Benefits: Rapid progress comes with substantial stakes-potential societal benefits countered by risks related to controlling AI development.
- Limitations Acknowledged: Hardware constraints and robotics bottlenecks may slow down the pace despite advances in software intelligence.
indian Opinion Analysis
the rapid advancement of large language models could greatly influence India’s technological landscape. Exponential growth offers exciting possibilities for sectors such as education, healthcare, and software development. Tools powered by advanced AI might enable more efficient processes across industries, reducing human effort for repetitive or intellectually demanding tasks.
However, significant caution is required considering broader risks like ethical concerns around job displacement in tech-heavy roles and societal changes stemming from increased automation. For India-a nation balancing ambitions for digital innovation with socio-economic complexities-the improvements also underline the importance of crafting thoughtful regulatory frameworks that prioritize inclusivity while embracing technology-driven productivity gains.In addition, hardware bottlenecks mentioned in the research highlight India’s need for strengthening domestic semiconductor production capacities and encouraging investments into high-performance computing infrastructure-a critical step toward sustaining competitiveness as global advancements accelerate.










Related Posts
Stay Informed With the Latest & Most Important News
Previous Post
Next Post



Advertisement





