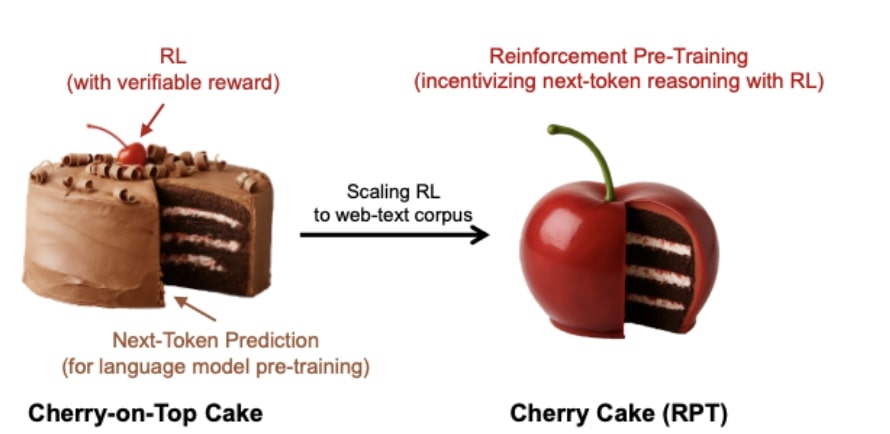
Reinforcement Pre-Training (RPT) is a new method for training large language models (LLMs) by reframing the standard task of predicting the next token in a sequence as a reasoning problem solved using reinforcement learning (RL).
Unlike traditional RL methods for LLMs that need expensive human data or limited annotated data, RPT uses verifiable rewards based on whether the model correctly predicts the actual next token from the vast amount of text data typically used for pre-training. This approach makes RL training scalable and general-purpose, as it leverages the existing text corpora, avoids the risk of reward hacking seen in learned reward models, and encourages the model to engage in a deliberate reasoning process before making predictions, promoting deeper understanding over simple memorization.
Core method RPT
At each token position in a text sequence, the model first generates a reasoning trace (chain-of-thought) and then predicts the next token.
If the prediction is a valid prefix of the ground-truth continuation, a reward is assigned.
Multiple rollouts are used per context, and the model is trained via on-policy RL.

Better than standard pretraining
RPT significantly outperforms standard next-token prediction and chain-of-thought reasoning baselines (without RL), achieving higher accuracy on tokens of varying difficulty and even rivaling larger models in performance.
RPT-14B, for instance, matches or exceeds R1-Qwen-32B’s accuracy on the OmniMATH benchmark.

Experiments demonstrate that RPT significantly *improves next-token prediction accuracy**, shows consistent performance gains with **increased training compute**, offers a **stronger pre-trained foundation* for subsequent RL fine-tuning, and *enhances zero-shot performance* on various reasoning benchmarks compared to models trained with standard methods, even outperforming larger models in some cases. The analysis of reasoning patterns confirms that RPT fosters a different, more inferential thinking process compared to standard problem-solving approaches.
Strong scaling laws
RPT exhibits clean power-law scaling with respect to training compute across difficulty levels, with prediction accuracy consistently improving as compute increases, and fitting closely to theoretical curves.

Promotes structured thinking
Analysis of reasoning traces reveals that RPT-14B employs more hypothesis generation, deduction, and reflective patterns compared to traditional problem-solving models, supporting the claim that RPT fosters deeper reasoning habits during training.
Great paper showing a new pre-training paradigm for scaling LLMs.


Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.