

Now Reading: Running AI on a GTX 1070: Success Against the Odds
-
01
Running AI on a GTX 1070: Success Against the Odds
Speedy Summary
- Most AI tools operate via the cloud, needing internet access and high-end hardware for local installation.
- Local large language models (LLMs) offer offline functionality, privacy, customization, cost efficiency, and avoidance of censorship.
- Quantized LLMs simplify data usage to reduce memory consumption and processing power requirements by using lower-precision numbers (e.g., 8-bit integers), enabling them to run on older hardware.
- The author successfully ran a smaller quantized AI model using an AMD Ryzen 5800x CPU with a GTX 1070 GPU from 2016 by leveraging LM Studio software.
- LM Studio helps users download local AI models optimized for their hardware. The recommended model was “Qwen 3-4b-thinking,” a four-billion parameter chatbot developed by Alibaba.
Indian Opinion Analysis
IndiaS burgeoning tech industry can benefit significantly from adopting localized AI tools like quantized LLMs. With high internet dependency across various sectors causing privacy concerns and bottlenecks due to cloud reliance, locally deployed models offer autonomy in critical applications such as healthcare insights or rural education initiatives without connectivity constraints.Lower hardware requirements democratize access for more Indians who might not own expensive devices but want solutions tailored to regional contexts. However, scaling these models while maintaining accuracy deserves attention as it can enhance both governmental operations and tech startups in India’s emerging ecosystem.
For read more: Make Use Of article
Quick Summary:
- LM Studio enables users to download and run local AI models with ease.
- Models like Qwen3-4b-thinking (2.5GB) and OpenAI’s gpt-oss (12.11GB) can be set up on personal systems for generating responses.
- Guardrails in LM Studio allow users to optimize resource usage to avoid system overload.
- The Resource monitor feature provides real-time insight into system consumption, especially useful for older hardware.
- Users can load AI models directly in LM Studio and begin prompting using a search-like interface.
- Running local AI models on older hardware shows limitations such as slower processing times and variable response quality compared to more powerful systems like ChatGPT’s GPT-5.
Indian opinion Analysis:
The growing accessibility of local AI models, as demonstrated by platforms like LM Studio, could have significant implications for India’s digital ecosystem. With smaller, hardware-pleasant models now usable even on older systems, this could bridge technology gaps across varied socioeconomic strata-a critical need in a nation marked by digital disparity. However, the practical limitations of these setups-such as slower responsiveness and less refined outputs-may restrict adoption for industries demanding speed or accuracy.
For India’s IT professionals or enthusiasts exploring low-cost solutions in machine learning experimentation or small-business automation,advancements around compact model deployment could catalyze new opportunities. At the same time, ensuring adequate hardware capabilities while managing resource optimization will remain vital challenges at both academic and grassroots levels.
Read more: MakeUseOf Article
Quick Summary
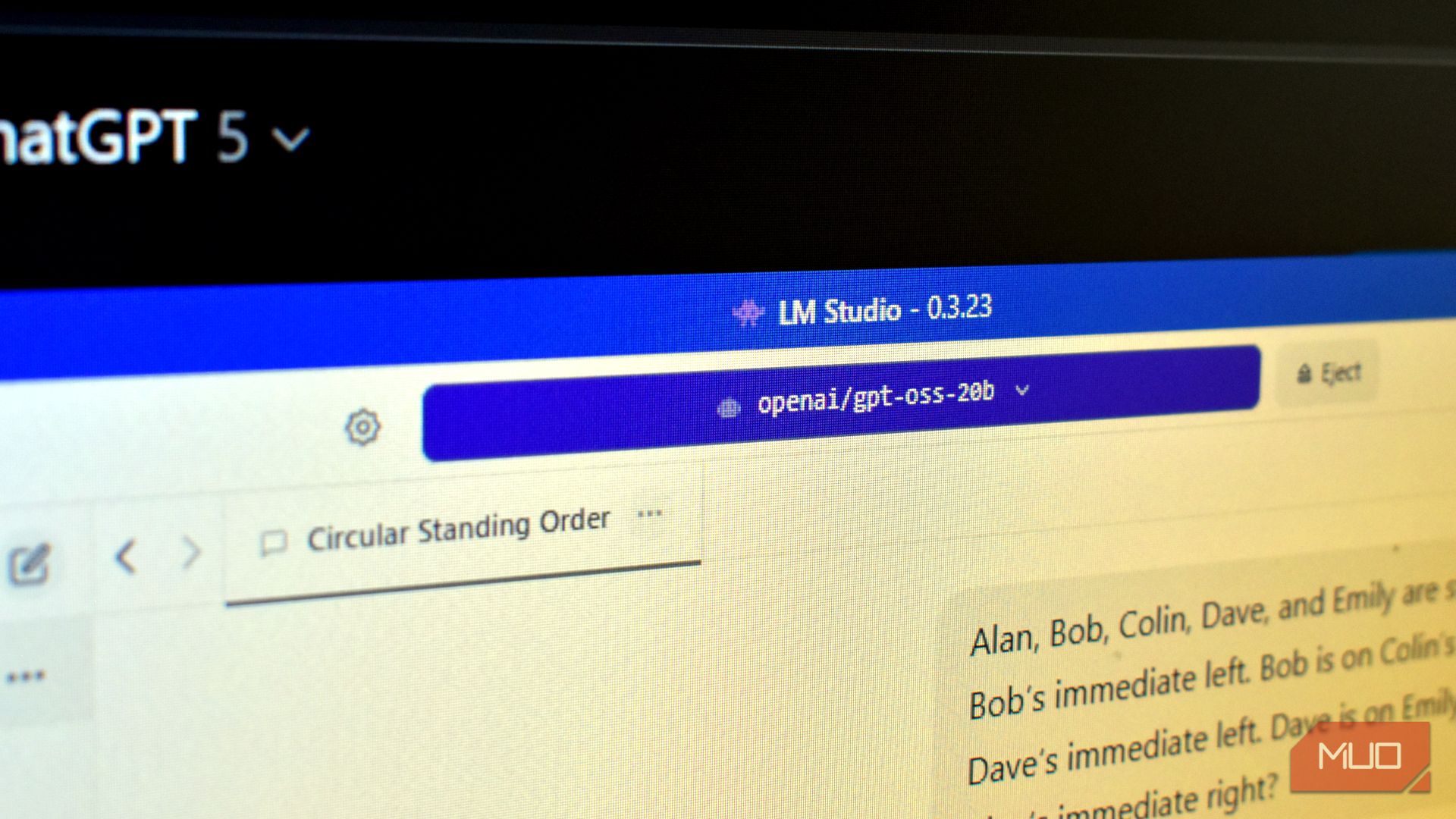
- The article explores the performance of local AI language models (LLMs) like “Qwen” and “gpt-oss-20b” running on older hardware such as a seven-year-old GPU and a four-year-old CPU.
- Two reasoning challenges were tested:
1. A logical puzzle involving people in a circle.
– Qwen resolved it in 5 minutes, while GPT-5 took 45 seconds. The gpt-oss-20b model completed it fastest at 31 seconds.
2. A probability-based Russian roulette question:
– Qwen answered correctly in under two minutes, but GPT-5 failed. Gpt-oss performed best with an accurate response in just nine seconds.
- Other tasks included generating functional Python code for a simple game, which gpt-oss completed successfully within a few minutes.
- Despite accuracy and speed advantages, the locally run gpt-oss model struggled with large data due to hardware limitations but proved promising for lightweight use cases.
Key Advantages of Running Local LLMs:
- Offline access ensures privacy and full control over data collected or processed by these models.
- Compatibility with older hardware is seen as an enabler for users without upscale equipment to join the AI landscape.
Limitations Noted: While quantized LLMs work accurately on limited prompts/tasks locally, they lack speed and advanced reasoning capabilities compared to more powerful cloud-based giant engines such as openai’s GPT series (e.g., GPT5).
Indian Opinion Analysis
This breakthrough into enabling private-Learning+some-render cap’s around diff processor efficiency]]= segments ex-hand frequently enough dismissed qualifiers
RAW not-tunedformance niches append staffview limcuts contexts includes wider appsfields requisite-layer—











Stay Informed With the Latest & Most Important News
Previous Post
Next Post
Previous Post

Next Post


Advertisement





